What is automated grading?
Automated grading refers to the use of technology to evaluate and score assessments without manual intervention. This includes rule-based grading systems for objective questions and more advanced tools like AI and machine learning models for evaluating subjective responses such as essays, interviews, and short answers.
These systems are widely used in education and corporate training to reduce grading time, ensure consistent evaluation, and provide instant feedback. Automated grading isn't limited to AI; it also encompasses evaluation techniques that apply predefined rules and functions
Key takeaways
- Automated grading increases efficiency, consistency, and scalability in assessments while ensuring objectivity, fairness, and bias-free evaluation, promoting equality among all test-takers.
- TestInvite supports diverse grading types: objective questions like multiple-choice, matching, or open-ended questions like short answer, essay, coding, and video/audio.
- Objective questions are graded instantly using answer keys, custom rules and AI evaluation.
- Subjective questions can be evaluated using rubrics, rules, or custom logic functions with optional AI assistance.
- TestInvite’s automated grading features allow for highly flexible scoring through custom functions AI prompts..
- All grading is integrated with real-time feedback and analytics to improve the test-taker experience and support informed decision-making.
How does automated grading work?
At the core of automated grading is the principle of evaluating responses against predefined criteria. TestInvite offers multiple grading methods that can be used alone or in combination to fit different assessment needs.
Below are detailed examples showcasing how automated grading works in diverse contexts using TestInvite's capabilities, including rule-based, rubric-based, function-based and AI evaluation systems. These reflect real-life use cases in education, recruitment, and skills assessment.
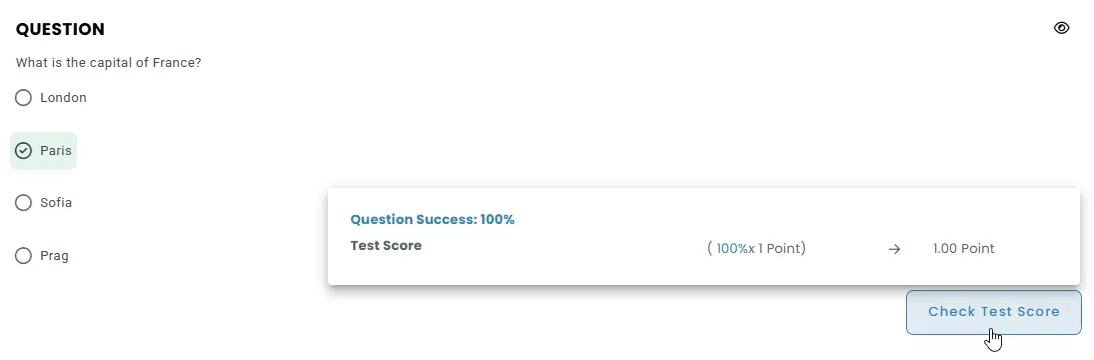
1. Objective question grading
All objective question types—including multiple-choice, matching, sorting —can be automatically graded. Each response is scored based on the correct answers or validation logic defined by the test author.
2. Rule-based evaluation
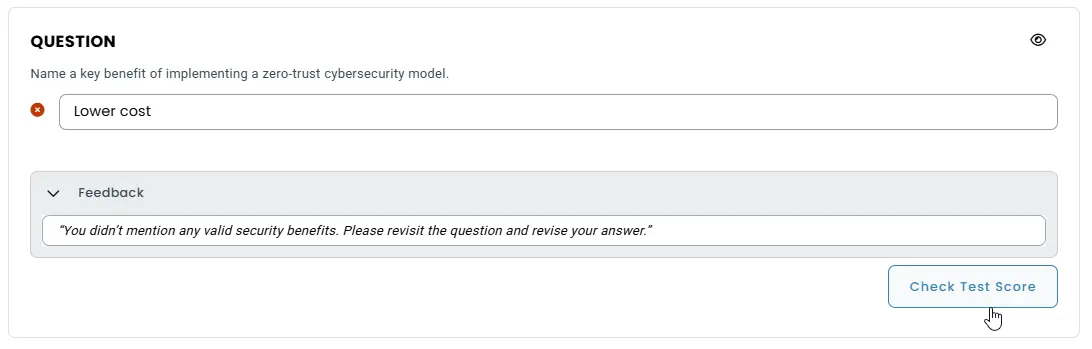
Short-answer, numeric input and custom response questions can be graded through logical text rules. These rules match expected inputs using exact string matching, regex, or semantic equivalents. If a response fails to meet a rule, the system can trigger a tailored feedback message. This approach helps automate nuanced grading across a wide variety of answer patterns.
Example Short Answer Question – Rule-Based Grading
Question:
Name a benefit of implementing a zero-trust cybersecurity model.
Context:
This question is part of a basic cybersecurity certification exam.
Grading Logic:
Evaluated using answer rules in TestInvite.
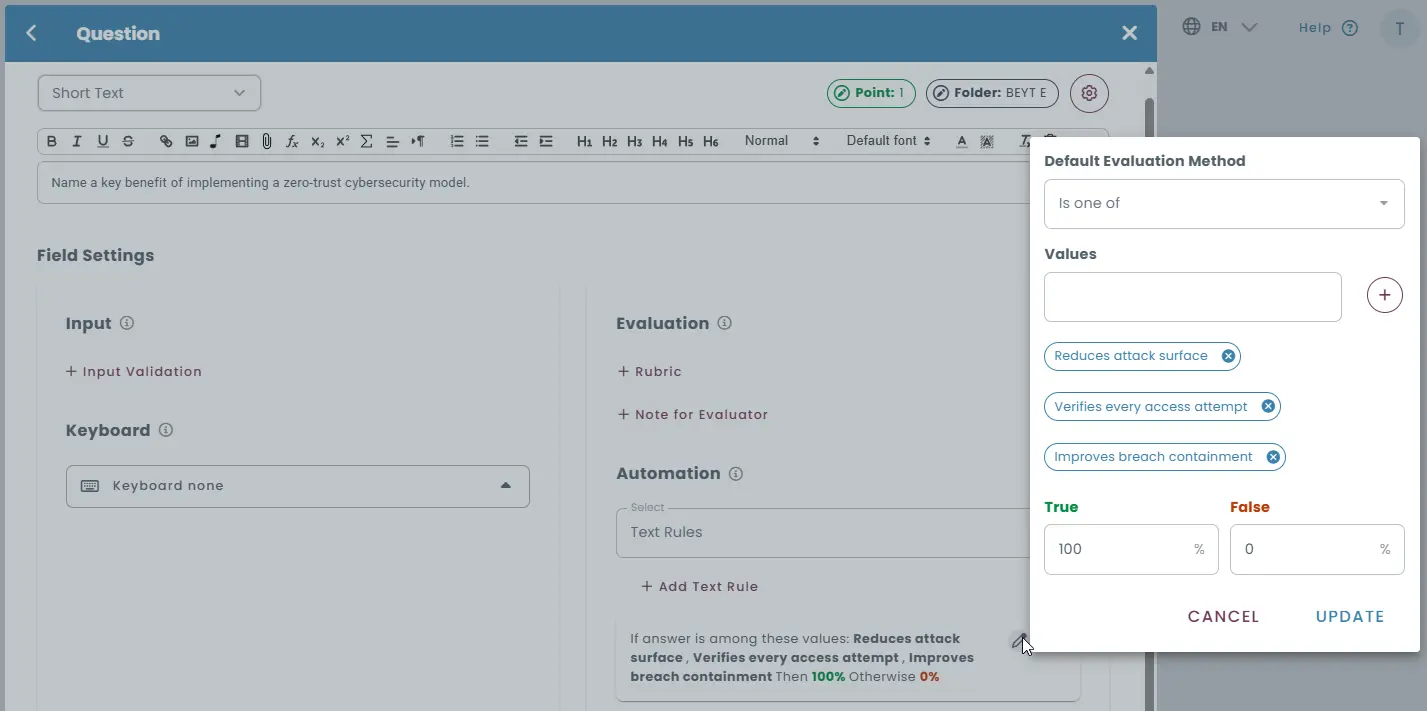
Rules Configured:
Response must include at least one of the following valid ideas (or paraphrased variants):
- "Reduces attack surface"
- "Verifies every access attempt"
- "Improves breach containment"
Feedback Logic:
If no valid ideas are detected, the system prompts the test-taker with:
“You didn’t mention any valid security benefits. Please revisit the question and revise your answer.”
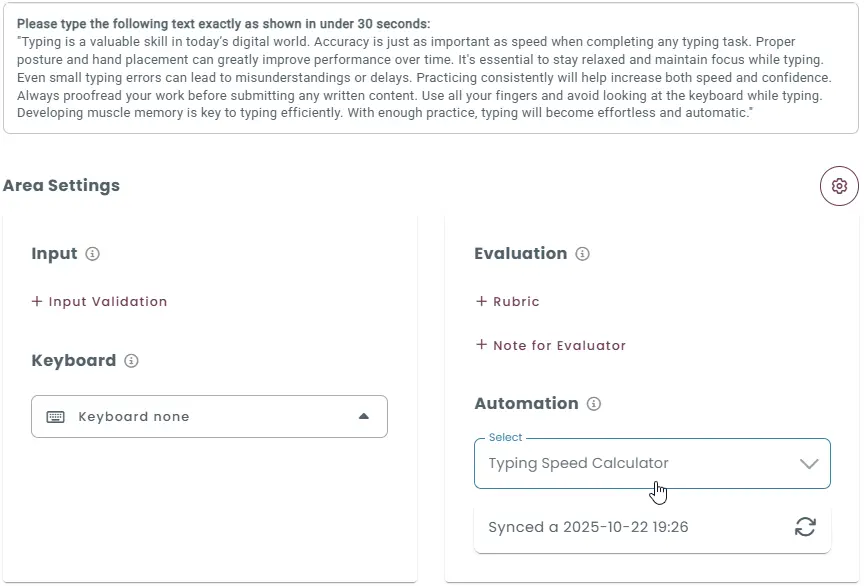
3. Function-based evaluation
TestInvite supports custom grading logic via functions. This allows advanced evaluators to:
- Apply regex or string comparisons
- Incorporate timing, punctuation, or formatting conditions
Apply weighted, partial, or negative scores
- Build custom validators for technical, domain-specific content
Function-based evaluation is an excellent tool for typing tests.
5. AI-assisted grading
TestInvite integrates with large language models (LLMs) to provide deeper analysis of open-ended question types—from long-form text to audio/video interview responses and coding exercises. AI can:
- Analyze grammar, tone, and logic
- Match responses against rubrics
- Provide a suggested score and rationale
This feature is best used with clear instructions, and/or defined rubrics, with optional human oversight.
Example Essay Question & AI-Assisted Rubric-Based Evaluation
Subjective assessments like essays and audio/video responses are often evaluated using scoring rubrics, as they make it possible to define multiple scoring dimensions—such as argument quality, structure, grammar, or content relevance—and ensure a transparent, consistent evaluation framework for every response. Use your rubrics as prompts to harness AI’s like-clockwork efficiency, speed and consistent scoring.
Below is an example of an essay question and its AI-assisted rubric-based evaluation prompts:
Question:
“In your opinion, what role should artificial intelligence play in human decision-making in the workplace? Support your argument with examples.”
Context:
The test taker is a mid-career professional in a leadership training program.
Scoring Method:
Rubric-based evaluation using TestInvite’s built-in AI configuration.
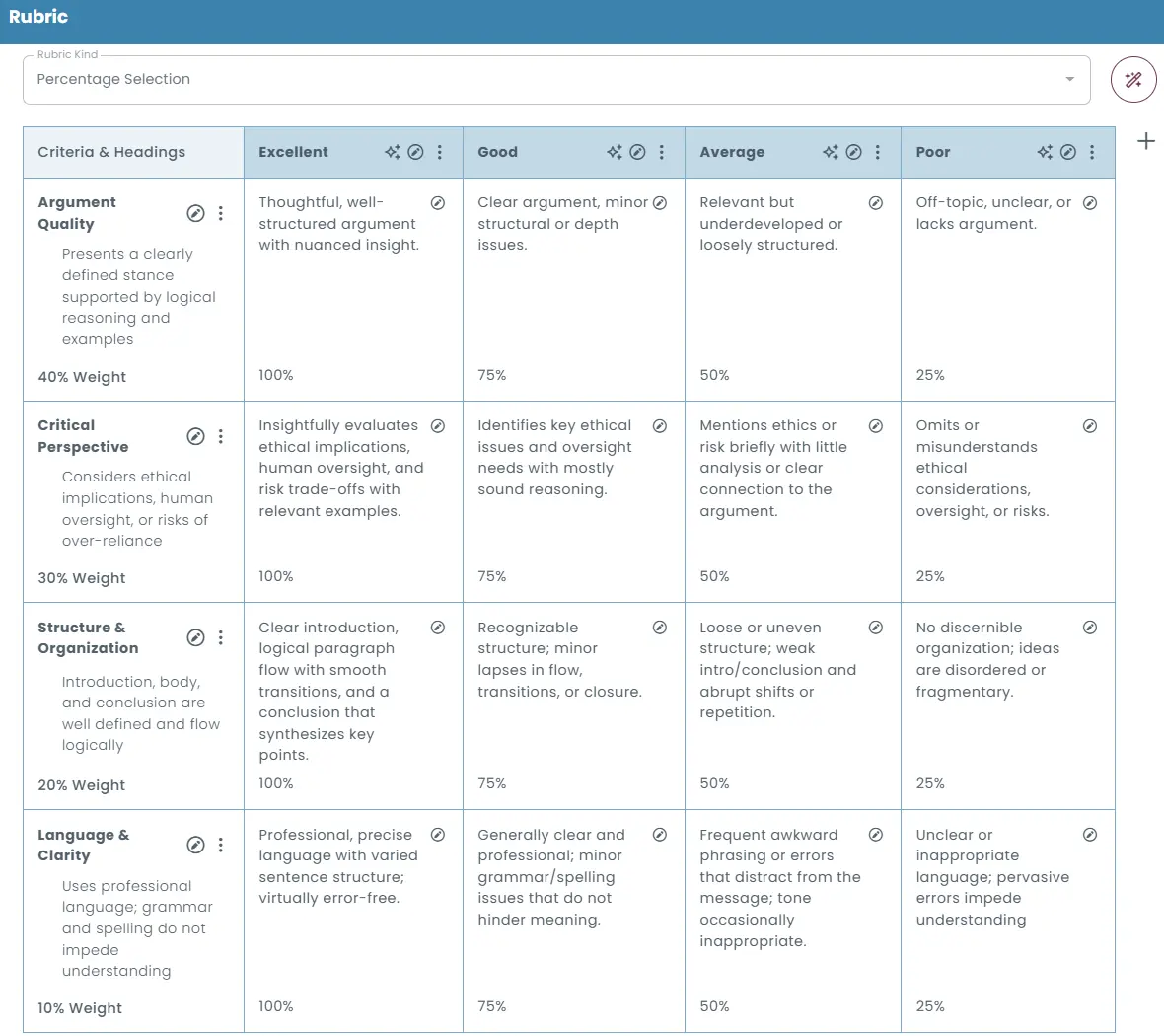
Evaluation criteria example using rubric instructions as AI prompt:
Argument Quality
100% — Thoughtful, well-structured argument with nuanced insight; clear thesis and logical progression; uses relevant, specific evidence and addresses counterarguments.
75% — Clear argument and thesis with mostly logical organization; adequate evidence, though depth or cohesion has minor issues; limited or partial engagement with counterpoints.
50% — Relevant idea but underdeveloped or loosely structured; thesis unclear; reasoning thin or repetitive; examples generic or incomplete; counterarguments ignored.
25% — Off-topic, unclear, or lacks a coherent argument; no defensible claim; reasoning absent or illogical; evidence missing or inappropriate.
Critical Perspective
100% — Insightfully evaluates ethical implications, human oversight, and risk trade-offs with relevant examples.
75% — Identifies key ethical issues and oversight needs with mostly sound reasoning.
50% — Mentions ethics or risk briefly with little analysis or clear connection to the argument.
25% — Omits or misunderstands ethical considerations, oversight, or risks.
Structure & Organization
100% — Clear introduction, logical paragraph flow with smooth transitions, and a conclusion that synthesizes key points.
75% — Recognizable structure; minor lapses in flow, transitions, or closure.
50% — Loose or uneven structure; weak intro/conclusion and abrupt shifts or repetition.
25% — No discernible organization; ideas are disordered or fragmentary.
Language & Clarity
100% — Professional, precise language with varied sentence structure; virtually error-free.
75% — Generally clear and professional; minor grammar/spelling issues that do not hinder meaning.
50% — Frequent awkward phrasing or errors that distract from the message; tone occasionally inappropriate.
25% — Unclear or inappropriate language; pervasive errors impede understanding.
Scoring Bands:
Excellent (100%) - Good (75%) - Average (50%) - Poor (<25)
Example Coding Question & AI-Assisted Evaluation
Coding assessments are often evaluated using automated grading, as they make it possible to define correctness, code Quality, problem-solving approach, robustness and originality/optimization while ensuring a transparent, consistent evaluation framework for every response. Like with other open-ended question types, you may use your rubrics as prompts to harness AI’s fast and impeccable code evaluating capabilities.
Below is an example of a coding question and its AI evaluation prompts, with and without the use of rubrics:
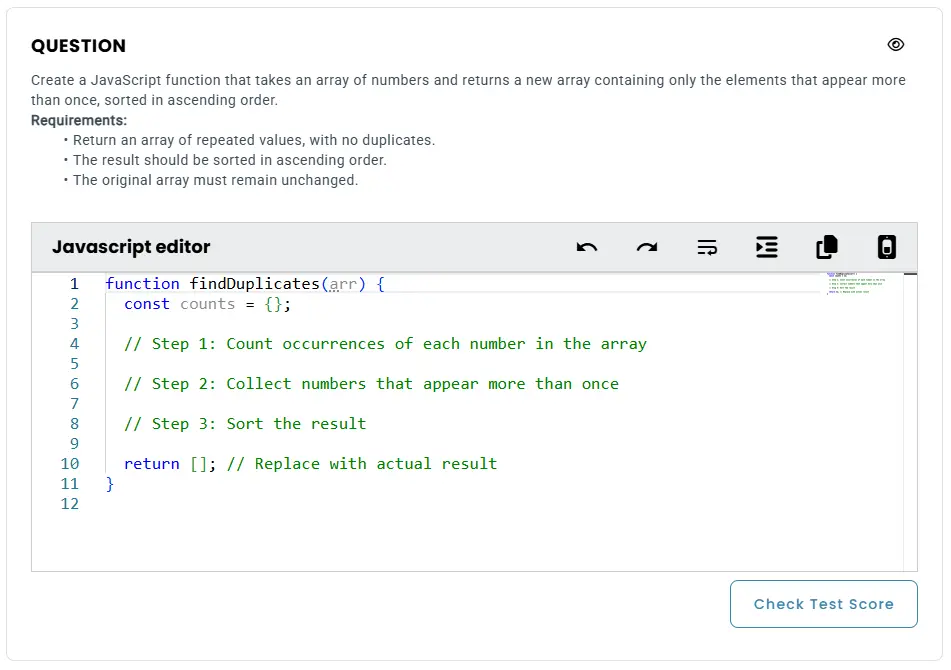
Question:
“Create a JavaScript function that takes an array of numbers and returns a new array containing only the elements that appear more than once, sorted in ascending order.
Requirements:
- Return an array of repeated values, with no duplicates.
- The result should be sorted in ascending order.
- The original array must remain unchanged.”
Evaluation Criteria:
“Evaluate based on the following:
- Correctness: Does the function return the correct output for valid input?
- Logic and structure: Is the solution logically sound and efficiently implemented?
- Use of recursion Did the candidate apply it appropriately?
- Readability: Are variable names meaningful, is the code organized and commented if needed?
- Edge cases: Does the solution account for empty arrays, non-array inputs, or deeply nested arrays?
Evaluation criteria example using rubric instructions as AI prompt:
While regular text info will provide the LLM a solid framework it can work with,, you can also use a rubric as an AI prompt for a more detailed evaluation.
Context:
The test taker is a professional under a coding skills assessment program.
Scoring Method:
Rubric-based evaluation using TestInvite’s built-in AI configuration.
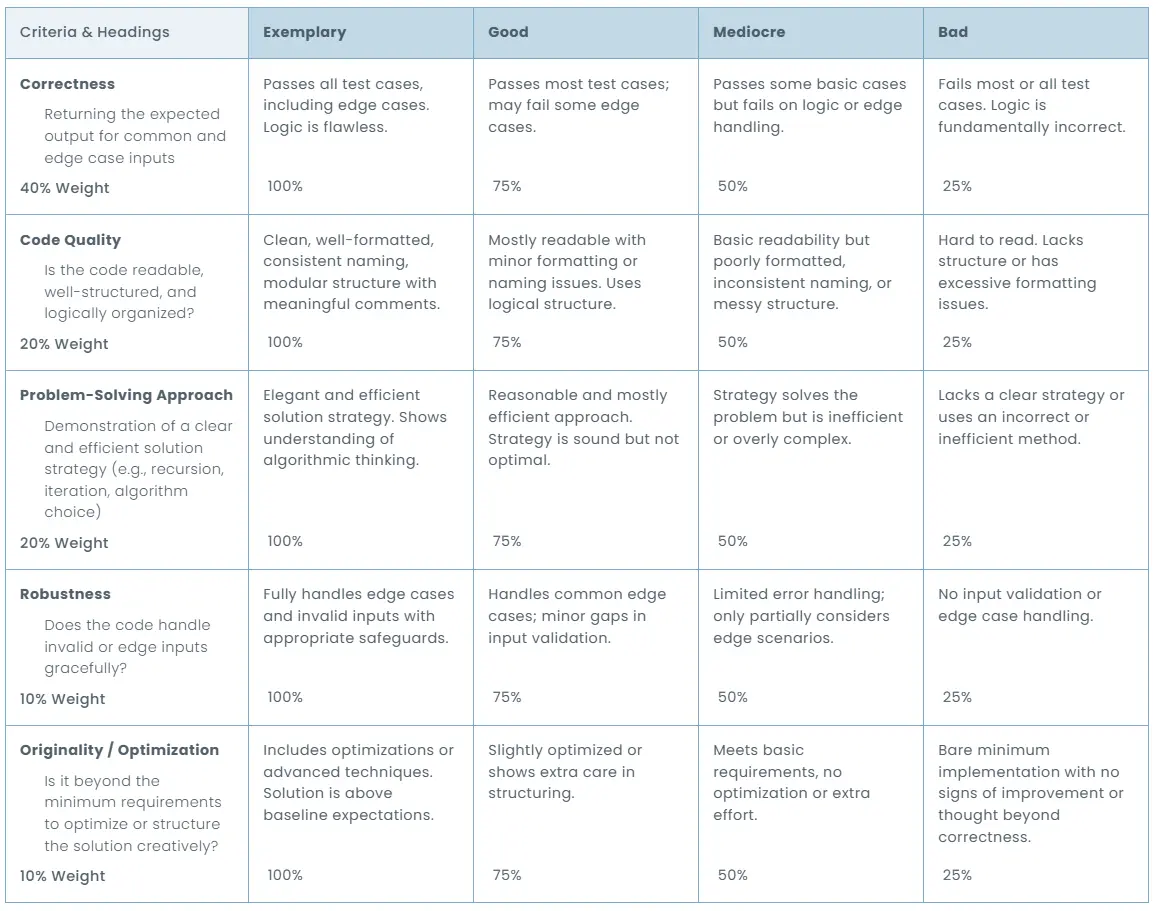
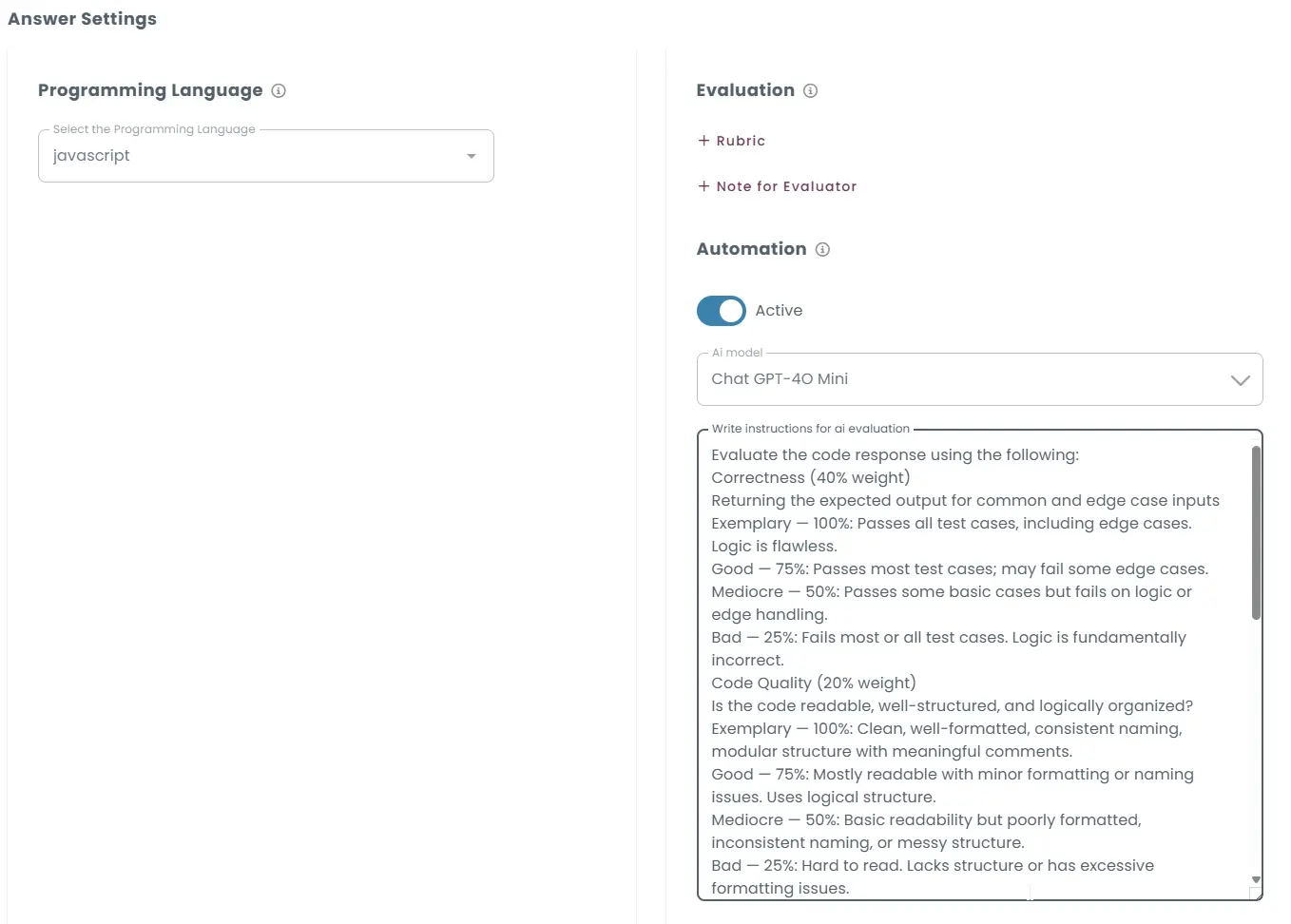
AI prompt:
Evaluate the code response using the following:
Correctness (40% weight)
Returning the expected output for common and edge case inputs
- Exemplary — 100%: Passes all test cases, including edge cases. Logic is flawless.
- Good — 75%: Passes most test cases; may fail some edge cases.
- Mediocre — 50%: Passes some basic cases but fails on logic or edge handling.
- Bad — 25%: Fails most or all test cases. Logic is fundamentally incorrect.
Code Quality (20% weight)
Is the code readable, well-structured, and logically organized?
- Exemplary — 100%: Clean, well-formatted, consistent naming, modular structure with meaningful comments.
- Good — 75%: Mostly readable with minor formatting or naming issues. Uses logical structure.
- Mediocre — 50%: Basic readability but poorly formatted, inconsistent naming, or messy structure.
- Bad — 25%: Hard to read. Lacks structure or has excessive formatting issues.
Problem-Solving Approach (20% weight)
Demonstration of a clear and efficient solution strategy (e.g., recursion, iteration, algorithm choice)
- Exemplary — 100%: Elegant and efficient strategy; shows strong algorithmic thinking.
- Good — 75%: Reasonable and mostly efficient approach; sound but not optimal.
- Mediocre — 50%: Solves the problem but is inefficient or overly complex.
- Bad — 25%: Lacks a clear strategy or uses an incorrect/inefficient method.
Robustness (10% weight)
Does the code handle invalid or edge inputs gracefully?
- Exemplary — 100%: Fully handles edge cases and invalid inputs with appropriate safeguards.
- Good — 75%: Handles common edge cases; minor gaps in validation.
- Mediocre — 50%: Limited error handling; partially considers edge scenarios.
- Bad — 25%: No input validation or edge case handling.
Originality / Optimization (10% weight)
Is it beyond the minimum requirements to optimize or structure the solution creatively?
- Exemplary — 100%: Includes optimizations or advanced techniques; above baseline expectations.
- Good — 75%: Slightly optimized or shows extra care in structure.
- Mediocre — 50%: Meets basic requirements; no optimization.
- Bad — 25%: Bare minimum; no signs of improvement beyond correctness.
Example Video Interview Question – Structured Rubric with STAR Pattern as AI prompt
Question:
Tell us about a time when you took initiative to solve a problem outside your role. What steps did you take, and what was the result?
Context:
Used in a corporate hiring process for team leads or cross-functional roles.
Grading Method:
AI assisted scoring using TestInvite’s rubric evaluation.
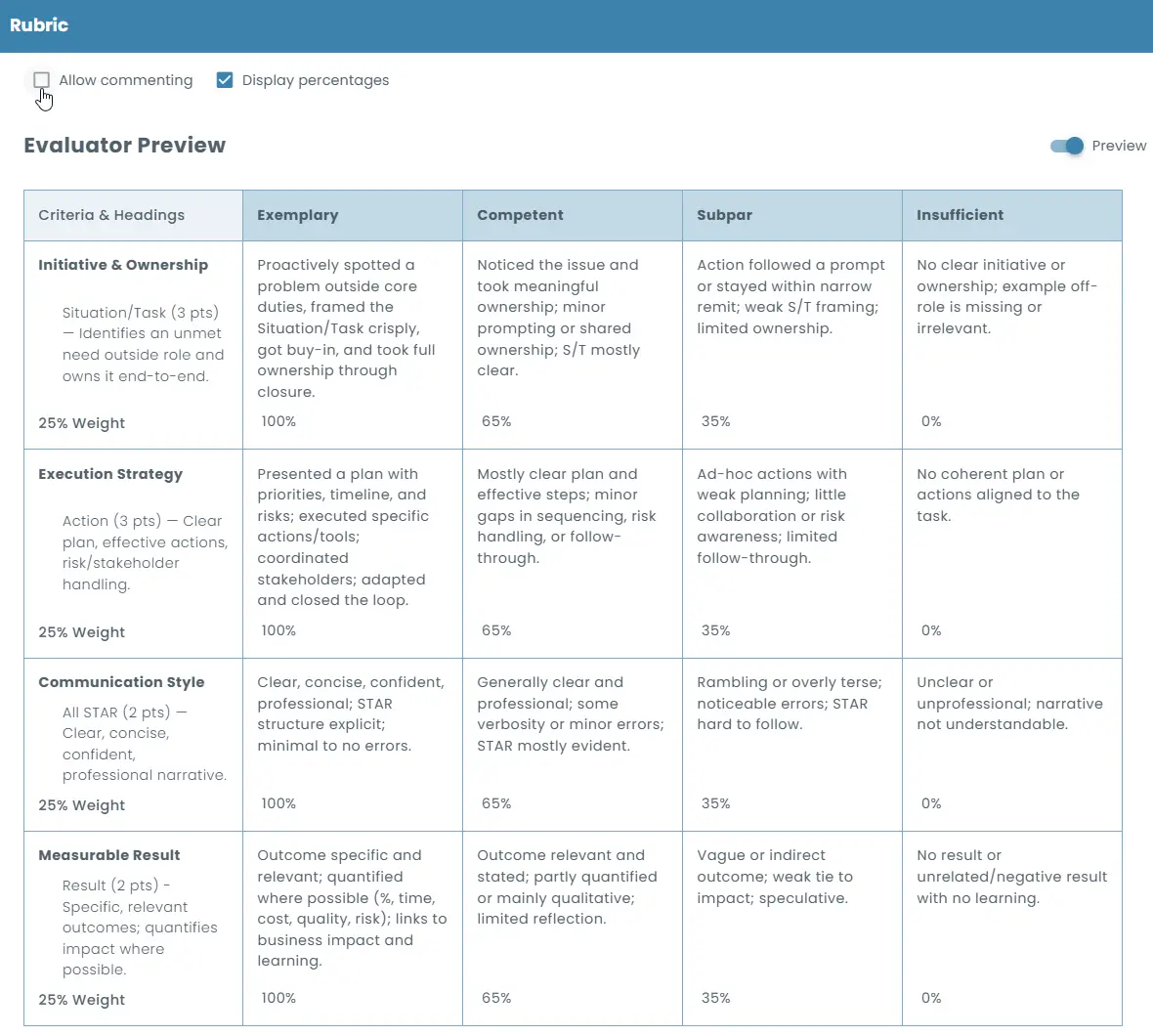
Evaluation Framework: STAR (Situation, Task, Action, Result)
1) Initiative & Ownership — Max 3 pts — STAR focus: S/T
100% — Proactively spotted a problem outside core duties, framed the Situation/Task crisply, got buy-in, and took full ownership through closure.
65% — Noticed the issue and took meaningful ownership; minor prompting or shared ownership; S/T mostly clear.
35% — Action followed a prompt or stayed within narrow remit; weak S/T framing; limited ownership.
0% — No clear initiative or ownership; example off-role is missing or irrelevant.
2) Execution Strategy — Max 3 pts — STAR focus: A
100% — Presented a plan with priorities, timeline, and risks; executed specific actions/tools; coordinated stakeholders; adapted and closed the loop.
65% — Mostly clear plan and effective steps; minor gaps in sequencing, risk handling, or follow-through.
35% — Ad-hoc actions with weak planning; little collaboration or risk awareness; limited follow-through.
0% — No coherent plan or actions aligned to the task.
3) Communication Style — Max 2 pts — STAR focus: all, emphasis on clarity
100% — Clear, concise, confident, professional; STAR structure explicit; minimal to no errors.
65% — Generally clear and professional; some verbosity or minor errors; STAR mostly evident.
35% — Rambling or overly terse; noticeable errors; STAR hard to follow.
0% — Unclear or unprofessional; narrative not understandable.
4) Measurable Result — Max 2 pts — STAR focus: R
100% — Outcome specific and relevant; quantified where possible (%, time, cost, quality, risk); links to business impact and learning.
65% — Outcome relevant and stated; partly quantified or mainly qualitative; limited reflection.
35% — Vague or indirect outcome; weak tie to impact; speculative.
0% — No result or unrelated/negative result with no learning.
Resources
(1) El Ebyary, K., & Windeatt, S. (2010). The impact of computer-based assessment feedback on student writing. Research and Practice in Technology Enhanced Learning, 5(3), 213–232. https://doi.org/10.1007/s40593-014-0026-8
(2) Utesch, M., & Hubwieser, P. (2024). Promises and breakages of automated grading systems: A qualitative study in computer science education. https://doi.org/10.48550/arXiv.2403.13491
(3) Güler, B., & Bozkurt, A. (2024). The role of artificial intelligence in assessment: A systematic review. Smart Learning Environments, 11, Article 6. https://doi.org/10.1186/s40536-024-00199-7
(4) Han, S., Kim, D. J., & Lee, J. (2025). Exploring the effectiveness and challenges of AI-assisted grading tools in university-level education. Applied Sciences, 15(5), 2787. https://doi.org/10.3390/app15052787
(5) Barrot, J. S. (2024). Automated scoring: Myths, mechanics, and modern use cases in large-scale education. Educational Assessment Research Journal, 16(2), 102–117.